
Selection of technologies to build an open source converged engineering platform
What are we trying to accomplish?
Project integration
In complex engineering projects, there are many moving parts and different fields play a role. Generally, there are mechanical, electrical/electronic, control/intrumentation, design, civil and documentation tasks that have to take place at the same time, on the same system and they all have some relationship with one another. Traditionally, these different aspects of a project have been worked on separately and the data exchange has taken place in a manual way (manual reviews, dumping data in a DB and sharing it, etc).
My goal would be to integrate all if not most of these disciplines within a single system that is fully integrated. As the reader goes through this article, hopefully, it will become clear why and how this vision may be achived.
Digital twin concept
A somewhat hot topic in the engineering world is the idea of a “digital twin”. This term refers to a digitalised model of a structure, machine, system, etc; that is fairly well developed and its outputs are compared to the real world system. The value that this adds to any project is the ability to test new changes or inputs in a digital system and see what it generates. This is a much cheaper way to test new ideas or inputs compared to their implementation in the real world. Another advantage is to compare the outputs that the real world system is generating with those of the computational model. If discrepancies appear, there may be an issue with the way the digital twin is modelled, and therefore, our understanding of the system behaviour; or that the real world system has an issue somewhere.
The theoretical project I am presenting here aims to create a fully integrated platform to develop projects and easily get a digital twin out of it; regardless of its complexity. The program should allow the visualization of the real system outputs on top of the digital twin.
Integration of information
All information in the system shall be integrated, easily accessible and auditable. Each component shall carry all of its relevant information for its analysis, construction, integration, changes and verification. All information shall be exportable in a clean and ordered manner for its auditability and use in external systems. Updates to the system should be reflected in the documentation. A flagging mechanism should be in place in such a way that if a relevant piece of data has been updated, which affects the documentation in some form, it will indicate the user that a potential update is needed; even if the user is not directly dealing with the part where the data was modified.
Automatic report generation will also be needed. For example, after the design, the user may want to know what parts are connected to another system and show the mechanical stresses that exist within each other. The documentation system shall be able to handle this case and display the relevant data (list of parts and stresses), but also pictures of the stresses if that is requested.
Technical excellence
There are plenty of different projects out in the wild: vehicles, raging from small scooters all the way to airplanes; powerplants, once again, raging from small wind farms to super critical ones; buildings, large and small, simple and complex; manufacturing lines; etc. All of them have a different set of requirements, and yet, they are quite similar at their core. Some common points are:
- They are all physical systems, which take up space and are made out
of parts; either big or small.
- The physical representation of a system will require some tool to do 3D representation, design and analysis.
- Have mechanical, fluid, electrical, electronic, etc components.
- These components tend to interact with each other and may require finer forms of analysis. A system analysis tool and specialised analysis/simulation programs will be required.
- Each project has their own set of documentation and a lot of it
stems from its parts, design and other related entities.
- The documentation for each component and its relation to the rest of the system would require an advance and complete documentation solution which can be customised.
All these projects require advance and complete software packages that need to satisfy the tasks asked for each system. Therefore, the best in class tools should be made available to the end users.
Additionally, some industries have to comply with standards, checks, safety regulations, traceability requirements, etc. Therefore, the proposed solution shall follow strict quality requirements. A selection of importan standards and guidelines for the system would be:
- General
- ISO/IEC 25019: Systems and software engineering, Systems and software Quality Requirements and Evaluation (SQuaRE)
- ISO/IEC 5055: Software measurement, quality measurement
- ISO/IEC/IEEE 90003: Software engineering, Guidelines for the application of ISO 9001:2015 to computer software
- TOGAF v10: The Open Group enterprise Architecture methodology and Framework
- (Cyber)Security
- IEC TS 62443: Security for industrial automation and control systems
- ISO/IEC 27001: Information security, cybersecurity and privacy protection; Information security management systems
- ISO/IEC 27002: Information security, cybersecurity and privacy protection, Information security controls
- OWASP: guidelines and best pactices
- Nuclear
- ASME NQA-1: Quality Assurance Requirements for Nuclear Facility Applications
- IAEA-TECDOC-1910: Quality Assurance and Quality Control in Nuclear Facilities and Activities
Technical goals
Technological openness
The software solutions shall be based on Libre Software as defined by the FSF and the GNU project. Any GPL compatible or incompatible license as defined here will be considered, however, compatible licenses will be preferred.
The choice of software freedom is at the core of the project. Libre software empowers the users and the companies to control how their project is handled, deployed, used and scaled. It also allows smaller deployments save on costs, as certification is generally not required for the tools. Larger deployments can have the different components certified if they so choose.
A software such as REUSE can be used to ensure the openness and license compatibility of the different components. It can be used as a simple SBOM (Software Bill Of Materials). SPDX identifiers will be used. However, for a more complete SBOM system, a framework such as CycloneDX from OWASP could or should be used. A longer and more complete list of software management tools can be found in the Open Source Tools section of the SPDX.
Flexibility of installation and deployment
The system must be as easy to install and deploy. The different parts that may be needed shall be simple to install in any *NIX environment by themselves and shall be simple to interoperate. They should also be able to use newer deployment methods, such as containers, to allow the users to pick their preferred installation method. Some installation systems that I would like to target are:
- Guix: it is a GNU project used to manage and deploy software independently of the Linux platform in use. It fosuces on flexibility of software choice (versions, patches, environments) and reproducibility.
- General package managers: the packages should be already packaged or be easily packaged on common package managers, such as APT for the Debian family, OpenSUSE’s zypper, Fedora’s DNF or FreeBSD’s and NetBSD’s port systems.
- Container technology such as Podman, Apptainer, Sarus, Docker, Kubertenes or Cloud Native Computing Foundation technology.
Centralization vs decentralization
Single engineering applications are normally always installed in the user’s computers where they run locally. However, large and complex engineering solutions generally require some IT/Computer knowledge in order to correctly deploy the software. This indicates an issue where, if several engineering tools and related technologies have to interact with each other, local deployments may not be easily achieved. For this reason, the project proposed here would have a fully centralized server, where all the computations, analysis and outputs take place on a centralized system. However, each individual tool can be installed locally by the users, because they should be simple to install and are libre, so they may work locally with data that can be downloaded from the centralized system.
Change traceability
Any serious project will grow in size, people and complexity. Tracking the different changes allows us to better understand the history of the project and give responsability to the users of the system. It also allows mistakes to be rolled back in case they were done accidentally or were issued incorrectly. Some of the most important tools in the software industry are specifically designed for this, such as Git, Fossil, Gitea, Dolt and others.
Flexibility for the user and third-parties
Each user of the system may have a different set of requirements. This particularity entails that the system will have to deal with an ever changing set of necessities and particularities. To be able to cope with this problem, a plug-in/extension system is generally used.
A plug-in system allows the users of a program to modify and fit the system to their needs, whatever those may be. It may also have advantages with regards to the development workflow, as new ideas could be prototyped quickly using the extension system. Finally, the extension system decouples the core of the application, which needs to be carefully monitored and taken care of, with the tools that a particular/non-standard task may need.
-
Integration with external tools
Integration with external tools could be directly dealt with by using the plug-in system. However, some standarised form of communication should be in place. Something like a REST API, GraphQL, or maybe even plain HTTP should be available so that other third-parties can consume data directly from the system. The project could make use of the FMI and FMU standards for this task.
Confidentiality
Large and complex projects are generally jointly carried out by several parties, each party shall only have access to a portion to the information in the project and not more. Within each organisation, different people may have a higher level of clearance than others. These particularities require that the proposed system be able to handle the information that each party receives to preserve the confidentiallity of the project. This must also take place while allowing users to still work on their specific system even if they don’t have access to all the information. This will require an authentication/authorisation system.
Correctness and integrity of the system
The system shall not break under incorrect changes. Mistakes should be detectable as early as possible withing the development workflow. The system should easily and quickly flag this issues and not allow a user to commit an incorrect change unless forced. Some early sanitation tests may be needed. Further systematic and automated checks, such as CI/CD, should function nicely within the system.
Feasibility and sustainability
If you, the reader, have reached this point, one big question that you may have is whether this is feasible and if so, sustainable economically. This is to be expected, the goals are too noble and too ambitious. After all, if such a system was desired by the industry, by companies, someone would have created it, no? The answer is yes, but not to the level I would like it to be. For example, BIM applications (Building Information Modelling), custom made digital twins and similar systems are close to what is being presented here. The world is moving towards them, even if they come with a huge cost. But my goal is larger and broader.
Here is the issue with the current market as I see it. The current tools available do not cover most needs of complex projects. Projects are increasing their complexity quite rapidly as technology advances and there is more demand for quicker and better results. Yes, BIM tools are great for civil works, but they mostly only display information and manage it. They don’t tend to do structural simulations, fluid analysis (HVAC, fire protection, wind loads, flood analysis…), electrical analysis, etc. Most other tools are similar. The ones that are very advance and highly integrated tend to be used only by their large corporate creators (Siemens, GE, Toshiba, etc) or they come at an absurd cost.
Ah, talking about costs… Tools that integrate a geometry kernel have been coming down in price. They used to cost upwards of 1000$ per license. Nowdays there are cheaper alternatives. However, the subscription licensing model is taking a hold of the market and it is becoming more obvious that companies intend to “vendor-lock” their users into paying for a product their entire lifetime. Other tools, such as system simulation tools (think of Simulink, Dymola, SimulationX, MapleSim, etc) also cost a sizeable amount, upwards of 15000$ a year per license. Then we have strucutral, fluid, electromagnetic analysis and design tools that usually cost upwards of 30000$ a year. Then we have ERPs that control and manage the general operations of the project, which, once again, cost an absurd amount. And the list goes on. If any complete, universal project management solution is to be created using commercially available solutions, a single license would cost more than 100000$ a year. Not only it would cost at least the sum of all of its parts, it would also be valued higher due to the added value of its integration capabilities and the higher cost of development. Some programs that try to achieve this capability already cost this much (upwards of one million dollars per license per year), and therefore, only a few people in large companies get to use them.
This is why I believe my idea is feasible and sustainable. A high quality and complete solutions is something the industry has been looking for since the invention of CAD and CAE tools came into the market. We have been getting there, but commercially available solutions will just simply not cut it. They either cannot provide all the features due to requiring third party programs or they are way to expensive to be manageable for consumers.
Technological analysis
Base programming language
Comparison table between programming languages
The following table indicates the most widely used programming languages in the so-called “back-end” server world. The reason to focus into these languages is because the system that is being proposed would need to have a very important server component to it.
| Language | Implementation(s) | Licence | Main Target | (Web) Frameworks | Community size | Success | Notes | Typed | Macros/Metaprogramming | Documentation tools |
|---|---|---|---|---|---|---|---|---|---|---|
| Elixir | Compiler for BEAM/JIT | Apache v2 | Servers, Web | Phoenix, Ash, (Nerves). UI: Liveview | Medium | Medium, growing | See1 | Runtime, annotations2 | Yes | First Class |
| Go | Compiler | BSD v3 | Servers, Applications | Gin, Fiber, Echo, Iris, Chi, Kratos | Large | Huge, growing | Yes, basic | No | Basic | |
| Java | JIT/Compiler | GPLv2 | Applications, Servers | Spring, Hilla, Vert.X, Quartus, Wicket, Dropwizard, Struts, Micronaut | Huge, “old” | Enormous, stable | Yes | No, use annotations | JavaDoc, Doxygen | |
| Kotlin | JIT/Compiler, Compiler | GPLv2 | Applications, Servers, UIs | See Java, Ktor, Javalin | Very large | Large, growing | Yes | No, use annotations | ||
| Clojure | JIT/Compiler, JS compiler | GPLv2 | Servers, Web, Applications | Kit, Biff, Pedestal | Medium | Medium | Yes, weak | Yes | ||
| JavaScript | Several | - | Web, Servers | Fastify, Meteor, KoaJS, ExpressJS UI: ReactJS, VueJS | Huge and very dynamic | Enormous, growing | See3 | No, objects | Basic (reflection) | JSDoc |
| TypeScript | Compiler to JS or WASM | Apache v2 | Web, Servers | NestJS, AdoniJS, Feathers, Ts.ED, Remix, Qwik UI: Svelte, Angular, NextJS, Vue 3/NuxtJS | Very large and growing | Large, growing | Yes | No? | TypeDoc | |
| PHP | Interpreter/JIT | PHP | Servers | Lavarel, Symfony, Yii, Slim, CakePHP, CodeIgniter | Very large, “old” | Enormous, slowing | See4 | Yes, objects | No, use attributes | phpDocumentor, Doxygen |
| Python | Interpreter, JIT, Compiler | PSF v2 & BSD0 | Servers, Applications | Django, Flask, Tornado, Sanic, Falcon | Very large | Huge, growing | Runtime, annotations | Yes (combination of different aspects) | Sphinx, Doxygen | |
| Ruby | Interpreter/JIT | BSD v2 | Servers | Ruby on Rails, Sinatra, Hanami | Huge, stable | Runtime | DSL | RDoc | ||
| Extras | ||||||||||
| Ada5 | Compiler | LGPLv3 | Applications, Servers | AWS | Very small | Low | Yes, very strong | No | ||
| Common Lisp6 | Several | - | Applications, Servers | TODO | Small | Medium, dwindling | Optional | Yes | ||
| Julia | JIT | MIT | Applications | TODO | Smallish community, scientific | Medium, growing | Yes, optional | Yes | ||
| Rust | Compiler | Apache v2, MIT | Applications, Servers | Tauri, TODO | Medium and growing | Growing | Yes | Yes |
[TODO] General notes about each programming language
The following sections contain oppinionated and potentially inaccurate information and incorrect conclusions.
-
[TODO] Elixir and the BEAM
-
[TODO] Go and the backend infraestructure world
-
JavaScript and its chaotic world
JavaScript and more recently TypeScript have grown tremendously in the past few years due to the prevalence of web technologies outside of the normal “web browsers”. Nowdays it generally ranks on the top 3 most-used programming languages. Modern applications, both in mobile and desktop are now using JS. Server backends are also being deployed with JS/TS thanks to Node and newer implementations such as Deno and Bun. This allows for the entire technology stack to be based on the same language and tooling. JS/TS in the backend, with tons of libraries to aid in database management, dependency management, communication with the clients and other services. JS/TS in the frontend, making it portable, dynamic, loaded with CSS and HTML.
However, the JavaScript ecosystem is filled with frameworks, tools and libraries that pop very often and dwindle. Some of the larger frameworks have stood the test of time and they are widely respected; both in the front-end and in the back end. However, due to the rapid nature of the ecosystem, braking changes and deprecations happen almost every month, which weights on any project. This is specially true for the project at hand as we would prefer to stay on the bleeding edge, but not get constantly cut. Moreover, the lack of typing and sometimes dubious dependency chains that some projects have, make it unsuitable for discussed project.
-
[TODO] Typescript, adding types to JS and some more
-
Java and JVM-based programming languages
Java is a very well-known programming languages. It is most likely in the top 5 most widely used programming languages. However, it shows its age in some of the design decisions (very heavy on object-oriented programming). Running the JVM is also a taxing process. Small SBCs7 generally cannot sustain it with some other processes also running (think of 1GB RAM SBCs). This goes against my wish to make the platform resource efficient. It is true that smaller and more resource aware JVM configurations are used (Android is a wonderful example of this), but that would require manual tweaking from the user side or more work from our side. Also, portability of the JVM to new architectures or systems is a difficult task due to the JVM’s size and complexity. Bootstrapping the JVM is also a problem as it is implemented in JAVA. Nonetheless, modern versions of Java, such as Java 21, are using newer syntax that greatly modernises Java. Plus there are projects, such as GraalVM that give Java some super powers.
-
Kotlin
Kotlin aims to be an improved, mordern version of Java. Google now recommends it for Android development and modern tools are designed for it. It tries to be compatible in nature with Java. There is also a native Kotlin compiler based on the LLVM toolchain.
-
Clojure
It is a modern, batteries included LISP. It can also be transpiled to JavaScript easily. It is desinged to use the power of the JVM while taking full advantage of LISP’s nature. It is probably the most widely used LISP in the “professional” world.
-
-
[TODO] PHP and its ancient yet alive world
-
[TODO] Python, good for everything… Great for nothing?
-
[TODO] Ruby and Rails
Conclusion, ranking of languages for this proposed project.
- Java: Kotlin seems to be picking up steam and it seems to be set
to overtake it. While Java keeps improving and has one of the
largest sets of libraries and programmers, and the enterprise world
seems to love it, its time seems to have passed. Oracle, the main
developer of Java, also has some shady history and it seems
untrustworthy, however, their behaviour should not impact the Java
ecosystem.
- Result: NO PASS, prefer Kotlin.
- Kotlin: modern Java. However it still requires the use of the
JVM and the native compiler cannot make use of the JVM tools and
libraries. There is also Jetpack
Compose and it web
counterpart,
Compose-Web, which
would allow developing fronteds with the same tools as Android and
desktop, but for the web. This allows using Kotlin + Jetpack as the
two main tools for the technology stack. Another issue is that
Kotlin has still not been bootstrapped, so a binary has to be used.
Nonetheless, Kotlin is the recommended language for Android
development, which means there are plenty of Kotlin programmers and
its sustainability is ensured in the long run.
- Result: KEEP AN EYE ON IT. But for the time being, NO PASS
- Clojure: loved by the LISP world. Has some great people behind
it and it can take full advantage of the JVM stack. With the use of
ClojureScript, it can also be used for the frontend, which greatly
reduces the technology stack. However, the same negative comments
regarding the JVM still stand. The community is also much smaller
than Kotlin’s, which in the long run can be problematic.
- Result: KEEP AN EYE ON IT. But for the time being, NO PASS
- JavaScript: for large projects, no, use TypeScript. JavaScript
is also a pretty much “web only” programming language, so native
tooling comes with a cost (everything runs on Electron basically).
- Result: NO PASS, prefer TypeScript for large projects.
- TypeScript: TODO
- Result:
- PHP: TODO
- Result:
- Ruby: TODO
- Result:
- Python: TODO
- Result:
- Elixir: TODO
- Result:
- Go: TODO
- Result:
-
Extras
- Ada:
- Result:
- LISP:
- Result:
- Rust:
- Results:
- Ada:
-
Ranking
| Language | Result | Position |
|---|---|---|
| Go | Batteries included language. Simple, fast, and widely used | |
| Elixir | Batteries included language. Resilient, functional, stable, lacks types | |
| TypeScript | Batteries included language. Flexible, widely used, chaotic | |
| Ruby | Simple, clean. With Rails, batteries included, mature ecosystem | |
| PHP | Mature community, ecosystem, ever-improving. Designed for backends | |
| Python | Simple to learn and use. Widely used in web and technical subjects | |
| Kotlin | Modern Java. Designed for large and complex systems | |
| Clojure | ||
| JavaScript | NO PASS. Use TypeScript for large projects | |
| Java | NO PASS. Use Kotlin | |
| Ada | ||
| Common LISP | ||
| Julia | ||
| Rust |
Database for knowledge management
Introduction to the conceptual design
In order to manage all the information that is going to be taken into account for a large project, the choice of a database is of upmost importance. As of the writing of this text, on the <2023-01-21 Sa>, here is what I imagine the data structure would look like:
-
First things first, how are the different components related to each other? This provides a high level overview of what an actual system would look like:
digraph name { edge [color=red, label="Electrical"]; "Electric\nGrid" -> "Electrical\nWire"; "Electrical\nWire" -> Controller -> Actuator -> "Electrical\nEngine"; Pump -> "Pressure\nSensor" -> Controller; edge [color=black, label="Mechanical"]; "Electrical\nEngine" -> Pump; "Reservoir" [style=filled, color=".7 .3 1.0"]; Pump [shape=polygon, sides=4, distortion=.7]; "Discharge" [style=filled, color=".7 .3 1.0"]; edge [color=blue, label="Fluid"]; "Pipe Inlet" [style=filled, color=".2 .2 .2"]; "Pipe Outlet" [style=filled, color=".3 .3 .3"]; "Reservoir" -> "Pipe Inlet" -> Pump -> "Pipe Outlet" -> "Discharge"; }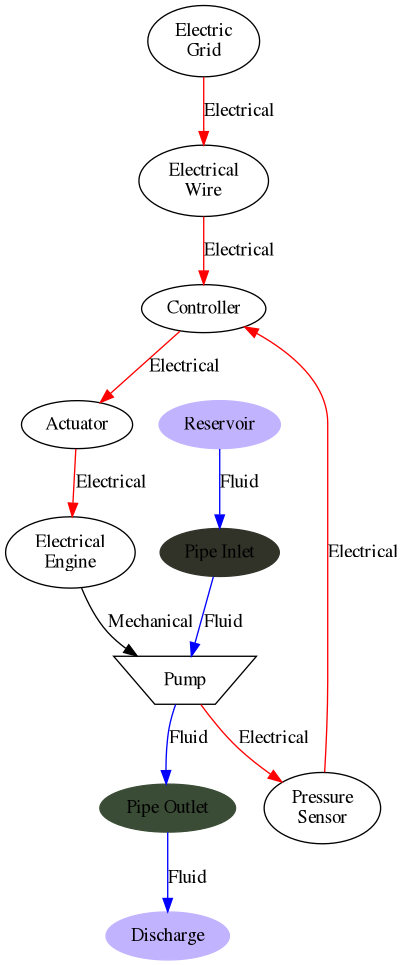
-
And each component would have the following information:
digraph name { graph [ label="Pump" labelloc="t" fontname="sans-serif" ] node [shape=record style=filled fontname="sans-serif" fillcolor=gray95 ] System_1 [shape=plain label=<<table border="0" cellborder="1" cellspacing="0" cellpadding="4"> <tr> <td> <b>Pump</b> </td> </tr> <tr> <td> <table border="0" cellborder="0" cellspacing="0" > <tr> <td align="left" >+ Inputs</td> </tr> <tr> <td port="ss1" align="left" >- Mechanical</td> </tr> <tr> <td> <table border="0" cellborder="1" cellspacing="0" > <tr> <td port="ss1" align="left" >Torque [F * L]</td> </tr> <tr> <td port="ss1" align="left" >Omega [T^-1]</td> </tr> </table> </td> </tr> <tr> <td port="ss1" align="left" >- Fluid</td> </tr> <tr> <td> <table border="0" cellborder="1" cellspacing="0" > <tr> <td port="ss1" align="left" >Mass Flow [M * T^-1]</td> </tr> <tr> <td port="ss1" align="left" >Pressure [F * L^-2]</td> </tr> </table> </td> </tr> <tr> <td port="ss2" align="left" >- Subsystem 3</td> </tr> <tr> <td port="ss3" align="left" >- Subsystem 4</td> </tr> <tr> <td align="left">...</td> </tr> </table> </td> </tr> <tr> <td> <table border="0" cellborder="0" cellspacing="0" > <tr> <td align="left" >+ Outputs</td> </tr> <tr> <td port="ss1" align="left" >- Fluid</td> </tr> <tr> <td> <table border="0" cellborder="1" cellspacing="0" > <tr> <td port="ss1" align="left" >Mass Flow [M * T^-1]</td> </tr> <tr> <td port="ss1" align="left" >Pressure [F * L^-2]</td> </tr> <tr> <td port="ss1" align="left" >Eff [-]</td> </tr> <tr> <td port="ss1" align="left" >...</td> </tr> </table> </td> </tr> <tr> <td port="ss2" align="left" >- Subsystem 2</td> </tr> <tr> <td align="left">...</td> </tr> </table> </td> </tr> <tr> <td> <table border="0" cellborder="0" cellspacing="0" > <tr> <td align="left" >+ Data</td> </tr> <tr> <td port="ss1" align="left" >- Geometry</td> </tr> <tr> <td> <table border="0" cellborder="1" cellspacing="0" > <tr> <td port="ss1" align="left" >Inlet Diam. [L]</td> </tr> <tr> <td port="ss1" align="left" >Height [L]</td> </tr> <tr> <td port="ss1" align="left" >Mesh [DATA]</td> </tr> <tr> <td port="ss1" align="left" >...</td> </tr> </table> </td> </tr> <tr> <td port="ss1" align="left" >- Manufacturer's Data [SQLite?]</td> </tr> <tr> <td port="ss2" align="left" >- Subsystem 2</td> </tr> <tr> <td align="left">...</td> </tr> </table> </td> </tr> <tr> <td align="left">+ Methods<br/>...<br align="left"/></td> </tr> </table>> ] }

Ideally, there would also be a second nearly identical copy of this data that would show real-world measurements, in real-time hopefully. That way users would be able to see what the real world system is generating and compare it directly to what the digital twin produces.
-
Comparison table for DB technologies
Note, the success column is subjective and the number of stars was taken mostly on the <2023-01-22 So>.
| Database | License | Language | Type | Drivers | Success | Use | Package presence | Notes |
|---|---|---|---|---|---|---|---|---|
| Apache v28 | C++ | Graph, Document, Search | Java, JS, Go, C#, community | 12.8k stars | ||||
| BadgerDB | Apache v2 | Go | NoSQL, Key-Value | Go | 11.7k stars | DGraph | Alternative to RocksDB, BoltDB. Embeddable | |
| ClickHouse | Apache v2 | C++ | Realtime, Analysis | |||||
| Cockroach | BSL9 | Go | Document, SQL | Go, JS/TS, Python, Java, Ruby, C, C#, Rust | 26.4k stars | Industrial | Kubertenes, Docker10, Manual11 | Focus on replication |
| Consul | BSL/MPL v212 | Go | Distributed NoSQl | HTTP API | 25.9k stars | |||
| CouchDB | Apache v2 | Erlang | Document | Java, Erlang, JS, Ruby, Python | 5.6k stars | |||
| DGraph | Apache v2 | Go | Graph | Go, Java, JS, Python, C#, gRPC | 18.9k stars | |||
| DuckDB | MIT | C++ | Data analytics | |||||
| EdgeDB | Apache v2 | Python | Graph-Relational | Rust, C#, JS, Python, Go | 10.2k stars | Based on PostgreSQL | ||
| etcd | Apache v2 | Go | Distributed Key-Value | Go, gRPC | 42.4k stars | |||
| FerretDB | Apache v2 | Go | Document, see PostgreSQL | Plenty13 | 10/1014 | Industrial | Alternative to MongoDB | |
| KeyDB | BSDv3 | C++ | Key-Value15 | Redis wire protocol | ||||
| Manticoresearch | GPLv2 | C++ | Search | MySQL wire protocol | 2.4k stars | Alternative to Elasticsearch | ||
| MariaDB | GPLv2 | C | SQL, Graph16, NoSQL17? | Plenty | 10/10 | Industrial | Everywhere | NoSQL requires BSL extension |
| Memcached | BSDv3 | C | Key-Value, Cache | Plenty | 12.4k stars | Industrial | Everywhere | Mostly only used as cache |
| Milvus | Apache v2 | Go, C++ | Vector(?) | Python, Java, Go, C++, JS | 14.7 stars | |||
| MindsDB | GPLv3 | Python | DB-AI | The DB of choice | 13.1k stars | DB data analysis | Not a real DB | |
| MonetDB | MPL-2 | C | OLAP | |||||
| MySQL | GPLv2 | C | SQL, NoSQL | Plenty | 10/10 | Insdustrial | Everywhere | Developed by Oracle |
| NebulaGraph | Apache v2 | C++ | Distributed Graph | Java, Python, C++, Go, Node | 8.5k stars | |||
| Neon | Apache v2 | Rust, Python | Serverless PostgreSQL | |||||
| OpenObserve | Apache v2 | Rust, Vue | ElasticSearch alternative | ElasticSearch API | ||||
| OrioleDB | MIT-Like | C, Python | Improved storage system for PostgreSQL | PostgreSQL | ||||
| Percona | MySQLv8 | C++, Go | Distributed MySQL, PostgreSQL | MySQL, PostgreSQL | 1k stars | |||
| PostgreSQL | MIT-like | C | SQL, Graph18, NoSQL, Timeseries19, Distributed20, Vector21 and more22 | Plenty | 10/10 | Industrial | Everywhere | |
| Redis | BSDv3 | C | Key-Value, Document | Plenty | 10/10 | Industrial, Cache | Everywhere | Advanced plugins are not libre |
| RethinkDB | Apache v2 | C++ | Realtime | JS, Python, Ruby, Java and community | 25.9k stars | |||
| Riak | Apache v2 | Erlang | Key-Value, Timeseries, S3 | |||||
| RocksDB | GPLv2 or Apache v2 | C++ | Key-Value | C++, Java | 24.4k stars | |||
| Rqlite | MIT | Go | Distributed SQL(ite) | SQLite | 13k stars | |||
| ScyllaDB | AGPL-3.0 | C++ | Distributed, NoSQL (Apache Cassandra compatible) | Same as Cassandra | TODO | |||
| SQLite | CC-0 | C | SQL, Document | Plenty | 10/10 | Industrial, Simple | Everywhere | Embeddable and Safety-critical |
| TDengine | AGPLv3 | C/C++ | Timeseries (IoT) | Java, Go, Python, JS, C#, Rust | 20.5k stars | |||
| TerminusDB | Apache v2 | Prolog/Rust | Graph | TODO | ||||
| TiDB | Apache v2 | Go | Distributed SQL | MySQL wire protocol | 33.2k stars | |||
| Typsesense | GPLv3 | C++ | Search | JS, PHP, Python, Ruby, community | 12.1k stars | Alternative to Elasticsearch, Algolia | ||
| VictoriaMetrics | Apache v2 | Go | Timeseries | TODO | Industrial use23 | |||
| Vitess | Apache v2 | Go | Distributed | MySQL compatible | 17.2k stars | Industrial use | Not compatible with MariaDB | |
| Weaviate | BSDv3 | Go | Vector | TODO | ||||
| YDB | Apache v2 | C++ | Distributed | YSQL | 3.2k stars | |||
| YugabyteDB | Apache v2 | C++ | SQL | PosgreSQL wire protocol | 7.4k stars | Goal: distributed PostgreSQL | ||
| ”Git” for DBs | ||||||||
| Dolt | Apache v2 | Go | Git for data. Only MySQL | - | 14k stars | |||
| DoltgreSQL | Apache v2 | Go | Git for data. Only PostgreSQL, beta | - | ||||
| ImmuDB | Apache v2 | Go | Immutable DB, Key-Value, SQL | Java, Go, C#, Python, JS | 8k stars | Tracks changes to the DB | ||
| Irmin | ISC | Ocaml | Distributed | |||||
| Litestream | Apache v2 | Go | Stream SQLite changes to storage | - | 8k stars | Make SQLite resilient | ||
| Prometheus storage | ||||||||
| Cortex | Apache v2 | Go | TODO | |||||
| HyperDX | MIT | TypeScript | TODO | |||||
| M3 | Apache v2 | Go | TODO | |||||
| Thanos | Apache v2 | Go | TODO |
A keen-eyed person may notice that there are no Databases written in Java, eventhough they are some of the most widely used and performant; just take a look that the Apache Foundation projects! The reason for this decission is that, as discussed in the Language Selection section, JVM based languages, while extremely performant, are not desired. The same logic applies in the Graphical User Interface section.
Platform integration technologies/BaaS
Something that may more closely bring the entire infrastrusture together is a Backend-as-a-Service solution. However, I have not taken a closer look into this possibility, as these BaaS seems to be modelled for more traditional web services in mind.
| Platform | License | Language | DBs | Auth | Success | Deployment | Notes |
|---|---|---|---|---|---|---|---|
| Appwrite | BSDv3 | TypeScript, PHP | MariaDB, Redis (GraphQL) | 28.7k stars | |||
| Nhost | MIT | TypeScript | PostgreSQL, Hasura/GraphQL | Hasura | 5.8k stars | GraphQL integration | |
| PocketBase | MIT | Go, (Svelte) | SQLite (WAL) | OAuth v2 | 20.3k stars | Very simple | Small embeddable and single server |
| Supabase | Apache v2 | TypeScript (React), Elixir | PostgreSQL (GraphQL) | 44.4k stars |
Choice for a DB
There are waaaaayyy too many DBs out there and some focus on specific tasks (that may be required for this project). Therefore, in order to help me organise my brain, I am going to focus only on the most well-known technologies and DBs that would fit the goal of this project. For example, disctributed DBs sound amazing, however, as we are mostly centralising the data, their main selling point does not apply for us.
-
Primary DB
For the primary DB technology, we have a few major and well-known choices. Traditional technologies include PostgreSQL and MySQL/MariaDB. There are also NoSQL, Graph, Timeseries, caching, etc; DBs that we could also make use of. For example, the final DB design may need to store unstructured data (NoSQL), time series data (Real time tracing, monitoring and simulation), etc.
Luckily, the distinction between traditional SQL DBs and “newer” paradigms such as NoSQL is fading away. Both PostgreSQL and MySQL nowdays can store arbitrary JSON data, just like any other NoSQL. They also have extensions/plugins that allow them to efficiently operate on timeseries information.
For this reason, in this section we are only going to focus on the major, well-known DBs and their capabilities (plus extensions) and see how they fair.
Primary DB ACID NoSQL Time series Graph Caching Key-Value Storage Distributed GIS Notes MariaDB Yes Yes Basic Yes Yes Yes Protocol Yes, Galera Yes No longer as compatible with MySQL MySQL Yes Yes Raw No Yes24 Raw Archival Yes, Galera, Vitess, Percona Yes Heavily developed PostgreSQL Yes Yes, FerretDB Raw, Timescale25 AGE No, OrioleDB Yes No YugabyteDB, Citus PostGIS Version updates are a pain still -
Primary DB choice
I think most of these DBs are very well suited for any given task. MySQL/MariaDB are probably more flexible than PostgreSQL and they are known for smoother migrations and updates. However, PostgreSQL has been always there, it is very widely used too and modern projects seem to be favouring it. It is also not dependent on Oracle (MySQL) or the MariaDB company, which, in my opinion, it is a plus.
-
-
Anciliary DB systems
The SQLite3 DB will be used in order to store general data that would be specific to manufacturers, standards (think of standard pipes or beams), etc. SQLite will be an ever present DB technology for this project.
-
Time series
These systems would read data from the analysis or real system and process, manage, store and display the information.
DB Prometheus VictoriaMetrics Timescale OSS -
Logging storage
For logging, I think the best way would be to just use something that is compatible with OpenTelemetry.
DB/System Loki Prometheus VictoriaLogs
-
-
Graph database?
A graph DB may be a great choice for this project, as the parts/machines/elements would constitude the nodes and the edges would indicate and show the relationship between those components. However, GraphDBs are quite nobel and they do not scale as much as traditional RDBMS. Most importantly, RDBMS were created to solve this problem, relations between data, which is the reason they are used in the backend of large social networks; eventhough GraphDBs would be perfectly suited for such task.
DB Notes ArangoDB DGraph Must be built in OSS mode Nebula Graph -
Analytical/OLAP database?
There are times where the user may want to run analysis on the project, such as “how many connectors (pipes, wires, etc) have a length over 10 meters?“. These kinds of queries can be done by any standard DB system. However, they may not be optimal as they are not created with data analysis in mind. For that reason, a specialised DB for this task may be needed.
Database Notes DuckDB In memory, has adapters to SQLite and PostgreSQL, PostgreSQL-like queries NocoDB Easy to use, tabular/Excel-like structure, low code MonetDB Mature
API design
Such a large and complex system as the one described here, must have a clear and flexible, yet resilient API. In the end, APIs are the interfaces between the different systems, and I believe the interfaces are just as important as the systems involved. For this reason, the correct technology to design and API and communication protocol has to to be chosen.
Here is a comparison of the major API specification formats.
| Technology | Protocol | Binary/Plain | Format | Schema Definition | Language support | Auth | Range support | Versioning | Tools |
|---|---|---|---|---|---|---|---|---|---|
| AsyncAPI | Agnostic | Plain | JSON/XML | YAML/JSON | Backend | Yes | Yes | Yes | Generator (code & documentation), Modelina (data) |
| OpenAPI | HTTP | Plain | JSON/XML | YAML/JSON | Plenty | Yes | Yes | Yes | Generator (code), ReDoc (documentation) |
| gRPC | HTTP 2 | Binary | gRPC/JSON | Protobuf | Plenty | Yes | No | Yes | Built-in |
| GraphQL | HTTP | Plain | JSON | GraphQL | Plenty | No | Manual | Versionless | Various |
Note: AsyncAPI is based on OpenAPI
IMPORTANT: For logs, metrics, traces and related systems, the OpenTelemetry standard will be used.
API technology choice
Taking a look at the comparison table above, AsyncAPI seems to be the better choice. It is based on OpenAPI, which grants it most if not all of the benefits, which are quite a lot. It also brings some goodies by itself. The biggest drawback is that it is newer and it has much less language support for code generation; which only focuses on the backend world. Hopefully in the future, AsyncAPI will grow to have a more vibrant and diverse ecosystem, just like OpenAPI.
For the time being and for initial prototyping, OpenAPI will be used in conjunction with OAPI-Codegen, which is fully implemented in Go.
There exists a pure Go implementation for AsyncAPI called AsyncAPI-Codegen which is inspired by OAPI-Codegen.
Authentication and Authorisation
The system will require an authentication system that shall allow users to log in and see their data. The authorisation component will take care of controlling the data that the users have access to. These two components are considered critical for the correct operation of the system.
The system shall use modern protocols in order to perform the aforementioned tasks. For this reason, the OpenID standard shall be used for authentication and OAuth 2 for authorisation. This will also enable external service providers to perform these tasks in case the user prefers it.
| Tool | Authentication | Authorisation | OpenID | OAuth 2 | ACL/RBAC… | DB used | SSO26 | MFA27 | GUI | Language | Notes |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Authelia | Yes | Yes | Yes | Yes | Yes | PostgreSQL, MySQL, SQLite | Yes | Yes | Yes | Go | |
| Authentik | Yes | Yes | Yes | Yes | Yes | PostgreSQL | Yes | Yes | Yes | Python | Change of license? |
| Authorizer | Yes | Yes | Yes | Yes | No | Many | Yes | Yes | Yes | Go | |
| Kratos, Hydra, Keto | Yes | Yes | Yes | Yes | Yes (Keto) | PostgreSQL, MySQL | Yes | Yes | No | Go | |
| Zitadel | Yes | Yes | Yes | Yes | Yes? | PostgreSQL | Yes | Yes | Yes | Go |
Auth* choice
Most, if not all of the options above, are very well equipped. They all seem mature and widely used in the industry. Kratos, Zitadel and Authelia seem to be the most prevalent solutions. Both Kratos and Zitadel are OpenID certified, which is always a plus, and they are also company backed, which gives them an edge in terms of support. However, Authelia seems to be the smallest one by code size and dependencies.
For the time being, Authelia will be used. But a component swap is possible in the future.
Graphical User Interface
In order for the users to have a pleasant and productive experience, the user interface should be chosen in such a way that it speeds programming cycles, is powerful enough to run all the required tools and produce high quality, flexible and intuitive UIs.
| GUI Toolkit | Multiplatform | Core Language | Programming language | Major requirements | GFX Pipeline | Wayland | Embedded WebView | Extra tools |
|---|---|---|---|---|---|---|---|---|
| Qt6 | Major OSes28 | C++ | C++, QML (JS/CSS), Python | C++ | Several, native | Yes | Yes | Large suite |
| Tk | Yes | C | C, Tcl, Python, Perl | C | Add-hoc | No | No | No |
| GTK 4 | Yes | C | C, C++, Rust, JS, Python, C#, Fortran, Ada; CSS | C | OpenGL, Vulkan | Yes | Yes | Yes |
| Electron | Major OSes | C++ | HTML, JS; CSS | C++, Chromium | OpenGL, WebGL | Yes | Native | JS ecosystem |
| Kirigami | Qt6 | QML | QML (JS/CSS), C++ | Qt | Qt | Yes | See Qt | See Qt, KDE Frameworks |
| ImGui | Yes | C++ | C++, several | C++ | Several, native | Yes | No | No |
| FLTK | Yes | C++ | C++ | C++ | Add-hoc | Yes | No | No |
| wxWidgets | Yes | C++ | C++, Python, Lua… | C++ | Add-hoc | Yes | Yes | Medium |
| Flutter | Major OSes | Dart | Dart | Dart | Impeller (modern) | Yes? | Yes | Dart/Flutter ecosystem |
| Game Engines | ||||||||
| Godot | Major OSes | C++ | GDScript, C++, C# | C++ | Vulkan, OpenGL | Yes | No | Game Engine |
| Raw Tools | ||||||||
| SDL3 | Yes | C | C, various | C | Several | Yes | No | GUI Platform |
| SFML | Yes | C++ | C++, various | C++ | Vulkan, OpenGL | Yes | No | Small |
| Raylib | Yes | C | C, various | C | Several | Yes | No | No |
| GLFW | Yes | C | C, various | C | OpenGL(ES), Vulkan | Yes | No | No |
[TODO] Choice for a GUI
[TODO] Scripting/Auxiliary language
| Language | TODO | Notes |
|---|---|---|
| Lua | ||
| Scheme | ||
| TCL | ||
| Python | ||
| JavaScript | See Duktape, QuickJS | |
| Lisp | See SBCL, ECL |
Choice for an Scripting language
Anciliary technologies
In order to carry out this grand vision, we need to make use of some of the best tools that exist in the libre world. Here are the following topics that need to be covered and their respective technological solution.
Visualisation
VTK and/or the Open Cascade (OCCT) geometry kernel, shall be used for the visualisation of the system. VTK offers different solutions: native, web (server side) and web (client side). Sidenote, for HPC system and modern (threaded, parallel) visualization there is the new VTK-m toolkit. Both technologies can be used together for different things; VTK for data and mesh visualization and Open Cascade (OCCT) for the geometrical descriptions. Projects such as Salome follow this approach.
License
VTK is licensed under the BSDv3 license. Open Cascade (OCCT) is licensed under the LGPLv2.1 with the Open CASCADE linking exception. VTK-m is licensed under the BSDv3.
Major dependencies
- Language
- Tools
System simulation
OpenModelica is a system simulation tool based on the Modelica programming language. It can be used to simulate electrical, mechanical, thermal, hydraulic, control systems among others. It can also couple them together.
Each component on the system could have its own Modelica equivalent model which could describe its behaviour. A complete interconected Modelica model should be auto-generated from the information in the model.
For example, lets assume we have the following linear system:
- Reservoir (ground level)
- Pipe
- Pump
- Pipe
- Reservoir (higher level)
The system should be able to generate each element’s Modelica block, connect it with its neighbours and correctly setup the values to generate a correct simulation, such as the different pressure losses that take place from the suction and discharge sides.
Note: it may be worth looking into CMB and SMTK as the simulation writers, drivers and couplers between programs/systems.
[TODO] Modelica libraries
The Modelica world is thriving and the community has already developped a vast ammount of libraries for a wide range of problems. One major issue is that most libraries use their own built in solutions in order to develop their behavior. One such example is that many thermal libraries all develop their own fluids module and library. This generally causes them to be incompatible with each other. The following libraries may be worth looking into in order to lighten up the development time.
License
OpenModelica is licensed under the GPLv3 or the OpenModelica License. Each library may have their own license.
Major dependencies
- Language: C++
- Tools
- Compiler:
- LLVM/Clang. License: Apache v2
- Qt (for the GUI). License: LGPLv3 with some modules under the GPLv3
- Modelica Standard Library. License: Modelica license29
- Compiler:
[TODO] Mechanical, structural and thermal simulations
Add CalculiX,
CodeAster,
OpenRadioss30
[TODO] Fluid simulations
Add OpenFOAM and
SU2, maybe
CodeSaturne.
Documentation and technical drawings
There shall be an automatic documentation system that takes the information from the project and translates it into printable paper. However, there are several ways this needs to be done with several alternatives.
Technical documentation
Technical documentation refers to P&IDs, control diagrams, electrical systems, electronic devices, etc. For each one of them there exists a Libre package able to deal with them.
-
Control diagrams, basic P&IDs and electrical systems
QElectroTech is a diagraming tool that can create control, electrical, hydraulic and thermal systems in a “flat” design and follows the IEC 60617. It can export designs as PDF or DXF. As of version 0.9 <2023-01-21 Sa> it does not seem to be able to create links to labels in other sheets. However, it lacks the general ASME Y14 symbology that is very commonly used, however, it could be added.
For electronic diagrams KiCAD could also be used. It integrates nowdays SPICE capabilities, otherwise Qucs-S could be used for simulations.
-
License
QElectroTech is licensed under the GPLv2 license. KiCAD is licensed under the GPLv3 license. Qucs-S is licensed under the GPLv2 license.
-
-
Blueprints, isometrics
FreeCAD is the only 3D CAD program that I am aware as of <2023-01-21 Sa> that can create 2D drawings starting from a 3D design. However, quite a bit of work would need to go into cooperating the system with FreeCAD.
-
License
FreeCAD is licensed under GPLv2 license.
-
-
Diagrams
Graphviz is a diagram creation tool which has its own programming language known as DOT. It can be used to create a plethora of diagrams as shown in its gallery. Other technology that could be used for this task is D2 (written in Go) and Mermaid (written in JS).
Text documentation
Text documentation refers to readable prose with potentialy some data intertwined in it. Here are the potential systems that could generate such documents.
-
LaTeX
LaTeX is the standard documentation format for high quality and academic works. The documents are written in plain text and then compiled to a working PDF. It has a lot of packages to create fancy structures, such as multipage tables. However, it requires the installation of its complete infraestructure. Ideally, LuaLaTeX should be used as it provides a more modern typesetting system with programmability in mind. One project that exploits LuaLaTeX’s programmability is SpeedData, which uses XML to automatically output beautifully typeset documents.
-
License
LaTeX is licensed under the LaTeX Public License (LPPL).
-
-
Pandoc
Pandoc is a document translator system. It takes a document from one format, and outputs it in another. This may not seem useful as a document system. However, the information within the system could be generated in a simple format, such as Markdown or reStructuredText and then process it into a final document. However, the generation of PDFs requires the use of LaTeX31.
Sadly, if Pandoc is built from source, it requires a gigantic array of Haskell modules and the GHC.
-
License
Pandoc is licensed under the GPLv2-or-later.
-
-
LibreOffice
LibreOffice is a libre alternative to the M$ Office suite. It can be used without the GUI (Graphical User Interface) using the
--headlessoption, which allows it to be used through its API. Final PDFs could be generated by creating a document writter either directly or using LibreOffice Base.-
License
LibreOffice is licensed under the GPLv3, LGPLv3 and MPLv2.
-
[TODO] Job management
The platform will require a job manager to control what analysis, simulation, tasks, etc are carried out. The job manager has the task to control the resources and notify when the job is done (among other secondary tasks). One technology that is commonly used in HPC to manage jobs is SLURM. Another powerful tool would be CMB from Kitware.
Note: it may be worth looking into CMB and SMTK as the simulation writers, drivers and couplers between programs/systems.
License
CMB is licensed under the BSDv3. SLURM is licensed under the GPLv2+.
[TODO] Deployment management
Deploying such a large and complex system requires some help to get it right. For this reason tools such as Kubernetes (K3S), Rancher, Warewulf, Cockpit may come in handy even if they are only used for internal development.
[TODO] Licenses
[TODO] Monitoring
Whatever the final implementation of the system is, it will require a level of performance monitoring. The actual project, such as simulations or real-time data, will also benefit from a built-in monitoring system. For this reason, the OpenTelemetry standard will be used. Two well-known solutions are provided: Prometheus is a monitoring system and a real-time database. It can be used alone or it can also be used with the other potential solution, Grafana, an observability and visualisation platform. Grafana can agregate data from other sources, such as Loki, PostgreSQL among others. Netdata is another very well-known solution.
License
Prometheus is licensed under the Apache v2 license. Grafana is licensed under the AGPLv3 license. Netdata is licensed under the GPLv3 license.
[TODO] Continious Integration, Deployment and Quality Management
Comparison of CI/CD technologies
| Tool | Type | CI | CD | Database | Frontend | GUI config | Containers | Language | Notes |
|---|---|---|---|---|---|---|---|---|---|
| BuildBot | Automator | Yes | Manual | SQLite | Yes | No | Manual | Python | Simple DIY |
| GitLab | Forge | Yes | Yes | PostgreSQL | Yes | No | Docker, Podman, Kubernetes | Ruby | |
| Woodpecker | Automator | Yes | Manual | SQLite, MySQL/MariaDB, PostgreSQL | Yes | No | Docker, Podman | Go | |
| Gitea Runner | Forge | Yes | Manual | SQLite, MySQL/MariaDB, PostgreSQL | Yes | No | Docker, Podman, Kubernetes | Go | |
| Act | Local Github | Yes | Yes | - | No | No | Docker, Podman | Go | |
| Tekton | Infraestructure | No | Yes | ? | No | No | Kubernetes | Go | For infra only? |
| Kraken | Automator | Yes | Manual | Docker compose… | Yes | Yes | Docker, LXD | Python | |
| Gitness | Forge | Yes | Yes | PostgreSQL, SQLite | Yes | No | Docker | Go | |
| Concourse | Automator | Yes | Yes | PostgreSQL | Yes | Yes | ContainerD | Go/Elm | |
| CDS | Automator | Yes | Yes | PostgreSQL | Yes | Yes | ? | Go/TypeScript | Large and complex |
| Agola | Automator | Yes | Yes | PostgreSQL, SQLite | Yes | No | Docker, Kubernetes | Go | Requires S3 and shared FS |
| Zuul | Forge | Yes | Yes | Many (SQLAlchemy) | Yes | No | Podman, Ansible | Python | Large system |
| SourceHut | Forge | Yes | Yes | PostgreSQL and Redis | Yes | No | Manual | Go, Python |
- Choice of CI/CD
[TODO] Technological dependency graph
All the technologies used in the project have dependencies. It is important to be aware of such dependencies in order to keep track of the potential issues, bugs, safety breaches and technological debt that could be accumulated over time. It is also important to track the tools and libraries used in case they want to be replaced in the future. Tools such as Guix can generate these graphs automagically, however, here, we will only focus on the major dependencies of the major components.
digraph {
layout=dot;
compound=true;
node [shape=rectangle];
subgraph cluster_Legend {
label = "Legend";
node [shape=point] {
rank=same
d0 [style = invis];
d1 [style = invis];
o0 [style = invis];
o1 [style = invis];
b0 [style = invis];
b1 [style = invis];
a0 [style = invis];
a1 [style = invis];
}
d0 -> d1 [label=Dependency];
o0 -> o1 [label="Optional Dependency" style=dashed];
b0 -> b1 [label="Build Requirement" style=dotted];
a0 -> a1 [label="Alternative Dependency" arrowhead=dot];
Optional [label="Optional", shape=rectangle, rank=min, style=filled, color=gray];
}
subgraph cluster_Development {
label="Development Tools"
Fossil [label="Fossil SCM", URL="https://fossil-scm.org"]
}
subgraph cluster_Server {
label="Server Architecture"
subgraph cluster_Networking {
label="Server/Networking"
NGINX [label="NGINX", URL="http://nginx.org/"]
Caddy [label="Caddy", URL="https://caddyserver.com/", style=filled, color=gray]
Lets_Encrypt [label="Let's Encrypt", URL="https://letsencrypt.org/"]
}
subgraph cluster_API {
label="API Design"
OpenAPI [label="OpenAPI", URL="https://www.openapis.org/"]
OAPI_Codegen [label="OpenAPI\nCodegen (Go)", URL="https://github.com/deepmap/oapi-codegen"]
// For the time being, leave AsyncAPI here
AsyncAPI [label="AsyncAPI", URL="https://www.asyncapi.com"]
Modelina [label="Modelina", URL="https://modelina.org/"]
AsyncAPI_Generator [label="AsyncAPI\nGenerator", URL="https://www.asyncapi.com/tools/generator", style=filled, color=gray]
Go_Watermill [label="Go Watermill\nEvent-Driven", URL="https://watermill.io/"]
}
subgraph cluster_Auth {
label="Auth*"
Authelia [label="Authelia", URL="https://www.authelia.com/"]
}
subgraph cluster_DB {
label="Server DataBase"
PostgreSQL [label="PostgreSQL", URL="https://www.postgresql.org/"]
// Timescale [label="Timescale OSS", URL="https://www.timescale.com/"]
PostGIS [label="PostGIS", URL="https://postgis.net/", style=filled, color=gray]
FerretDB [label="FerretDB\n(NoSQL)", URL="https://www.ferretdb.com/", style=filled color=gray]
AGE [label="AGE\n(GraphDB)", URL="https://age.apache.org/", style=filled, color=gray]
subgraph cluster_Observability {
label="Observability and Logging"
VictoriaMetrics [label="VicotriaMetrics", URL="https://victoriametrics.com/"]
VictoriaLogs [label="VictoriaLogs", URL="https://victoriametrics.com/"]
VictoriaLogs -> VictoriaMetrics
}
// Timescale -> PostgreSQL
PostGIS -> PostgreSQL
FerretDB -> PostgreSQL
AGE -> PostgreSQL
}
}
subgraph cluster_Tools {
label="Tools"
subgraph cluster_Documentation {
label="Document Generation"
LaTeX [label="LaTeX", URL="https://www.ctan.org"]
LibreOffice [label="LibreOffice", URL="https://www.libreoffice.org/"]
}
subgraph cluster_Analysis_Tools {
label="Analysis Tools"
OpenModelica [label="OpenModelica", URL="https://openmodelica.org/"]
}
subgraph cluster_Libraries {
label="Major Libraries"
BLAS [label="Lapack/BLAS", URL="https://www.openblas.net/"]
}
subgraph cluster_Client_Tools {
label="Client Tools"
subgraph cluster_GUI {
label="GUI"
QML [label="QML", URL="https://doc.qt.io/qt-6/qml-tutorial.html"]
Qt [label="Qt6", URL="https://www.qt.io/product/qt6"]
}
subgraph cluster_Geometry {
label="Geometry"
VTK [label="VTK", URL="https://vtk.org/"]
OpenCascade [label="OpenCascade", URL="https://dev.opencascade.org/"]
}
subgraph cluster_Datastore {
label="Data Storage"
SQLite [label="SQLite", URL="https://www.sqlite.org/index.html"]
}
}
}
subgraph cluster_Languages {
label="Programming Languages";
C_Compiler [label="C Compiler"];
Cpp_Compiler [label="C++ Compiler"];
Fortran_Compiler [label="Fortran Compiler"];
Python [label="Python", URL="https://www.python.org/"];
Go [label="Go", URL="https://go.dev/"];
JavaScript [label="JavaScript", URL="https://developer.mozilla.org/en-US/docs/Web/javascript"];
TypeScript [label="TypeScript", URL="https://www.typescriptlang.org/"];
Lua [label="Lua", URL="https://www.lua.org/"]
subgraph cluster_Build_Tools {
label="Build tools"
GCC [label="GNU C/C++/Ada/Fortran compiler", URL="https://gcc.gnu.org/"];
Clang [label="C/C++ LLVM frontend", URL="https://clang.llvm.org/"];
LLVM [label="LLVM compiler", URL="https://llvm.org/"];
CMake [label="CMake Build Tool", URL="https://cmake.org/"];
Ninja [label="Ninja", URL="https://doc.qt.io/qt-6/qml-tutorial.html"];
GNU_Make [label="GNU Make", URL="https://www.gnu.org/software/make"];
GNU_Autotools [label="GNU Autotools", URL="https://www.gnu.org/software/automake/"];
NodeJS [label="Node", URL="https://nodejs.org/en"];
}
}
//
// Development tools
//
Fossil -> C_Compiler [style=dotted]
//
// Server tools
//
// Networking
NGINX -> C_Compiler [style=dotted]
Caddy -> Go [style=dotted]
// Auth*
Authelia -> Go [style=dotted]
// API Design
OpenAPI -> OAPI_Codegen
OAPI_Codegen -> Go [style=dotted]
AsyncAPI -> NodeJS
AsyncAPI -> Modelina
AsyncAPI -> {AsyncAPI_Generator Go_Watermill} [style=dashed, arrowhead=dot]
Modelina -> TypeScript
Go_Watermill -> Go [style=dotted]
AsyncAPI_Generator -> JavaScript
// DataBases
PostgreSQL -> C_Compiler [style=dotted]
FerretDB -> Go [style=dotted]
VictoriaMetrics -> Go [style=dotted]
// Documentation
LibreOffice -> Cpp_Compiler [style=dotted]
LaTeX -> Lua
//
// Client dependencies
//
// GUI
QML -> Qt
Qt -> {Cpp_Compiler CMake Python} [style=dotted]
// Geometry
VTK -> {Cpp_Compiler CMake} [style=dotted]
VTK -> Qt [style=dashed]
OpenCascade -> VTK [style=dashed]
OpenCascade -> {Cpp_Compiler CMake} [style=dotted]
// Data Store
SQLite -> C_Compiler [style=dotted]
//
// Anciliary tools
//
OpenModelica -> Qt [style=dashed]
OpenModelica -> {BLAS C_Compiler Cpp_Compiler}
OpenModelica -> {CMake Fortran_Compiler} [style=dotted]
//
// Libary dependencies
//
BLAS -> Fortran_Compiler [style=dotted]
//
// Build dependencies
//
// Languages
C_Compiler -> {GCC Clang} [style=dashed, arrowhead=dot]
Cpp_Compiler -> {GCC Clang} [style=dashed, arrowhead=dot]
Fortran_Compiler -> GCC [style=dashed]
Python -> C_Compiler [style=dotted]
JavaScript -> NodeJS
NodeJS -> Cpp_Compiler [style=dotted]
TypeScript -> NodeJS
Lua -> C_Compiler [style=dotted]
// Build tools
Clang -> LLVM
GCC -> GNU_Autotools
GNU_Make -> C_Compiler [style=dotted]
CMake -> Cpp_Compiler [style=dotted]
CMake -> {GNU_Make Ninja} [style=dashed]
Ninja -> Cpp_Compiler [style=dotted]
}
To begin with, a prototype
Okay, after all these topics and discussions, I have reached some conclusions, but a lot more needs to be done than just write a few comparison matrixes and descriptions. Any project needs to start somewhere, a prototype needs to be created.
The technology used in any prototype should resemble the one in the final product, but it does not have to be the exact same. It is also useful to better understand the problem and the technical challenges associated with it. Even more, for my personal case, it will also serve as a training ground for me to learn a large number of technologies that I will have to use in the future. For that reason, here is the technology stack that I have chosen to begin with.
-
PlatformDatabase: PocketBaseSQLite This may seem like a stupid choice to begin with. However, it is quite intentional. Pocketbase provides a simple to use backend… Actually, it is too simple, but that is the point. It should allow for quick and easy testing of ideas. It uses SQLite behind the scenes, which for a simple prototype will be more than enough. It also brings some auth* utilities, management webpage and it is based on the Go programming language.
-
Visualization: OpenCascadeJS (OC.js) (an example of its use would be CascadeStudio). It is a “simple” JS/TS library that allows loading OpenCascade models and operations into the browser.
-
Frontend programming language: Vue 3 and TypeScript. As the Kitware stack makes use of Vue 3, it will be the JS/TS framework of choice. Some examples that consume Vue code are Trame, Glances and VolView. Vue also seems to be one of the fastest and largest JS/TS frameworks (source).
-
Backend programming language: Go. As PocketBase is written in it, it will be most helpful and make most sense to utilise the same technology that the selected backend uses.
A few more notes. The technology selection above does not necessarily represent the final technology stack. Here are a few examples:
- Database: a large system will require a more powerful and flexible DB infraestructure. DB systems such as PostgreSQL (with its different extensions) and MariaDB may be better suited for the final task.
- Backend programming language: while Go is a perfectly fine language for backends and it is already used in a ton of backend infraestructure, the Elixir programming language seems to focus quite nicely on reliability and resiliance. This is a very desirable property for the final product (plus it should be getting type support starting with v1.16). However, Common Lisp may be better suited in order to translate between all the different abstraction layers within the project (3D, Modelica, DB, interactions…). Finally, Ada may be a better choice if high quality standards are a must.
- Frontend programming language: the prototype will be based on web technologies. However, a native app for the final system may be more desirable. Maybe a platform like Salome could be leveraged to run the final user facing application, which would require the use of C++ and/or Python in this case.
- Mentioned as part of the goals of the project, the system should be able to run as a container(s). However, one interesting thing that may be worth looking into, is the use of Unikernels32 for enhanced security, performance and role separation.
[TODO] Add/assess technologies
Fluent-bit [https://fluentbit.io/]
Fluentd [https://www.fluentd.org/]
Earthly [https://earthly.dev/]
Aerospike [https://github.com/aerospike/aerospike-server]
DevPod [https://devpod.sh/]
Fuzzball (not open!) [https://ciq.com/products/fuzzball/]
eSim [https://esim.fossee.in/]
Replicad [https://replicad.xyz/]
ScanCode [https://github.com/nexB/scancode-toolkit]
Open Component Model [http://ocm.software/]
G+SMO [https://gismo.github.io/]
Base the interfacing of the different components on the FMI standard? It seems to be quite logical but I have no idea how it scales or whether it is even a good idea. Nontheless, this is the problem that is was created for. It may be worth taking a look at the example FMUs they provide.
Footnotes
Footnotes
-
TODO.
- Tools:
-
However, José Valim, the creator of Elixir has expressed his wish to push typed Elixir. ↩
-
Eventhough JavaScript is a rapidly growing (and already huge) ecosystem, it has quite a few notable drawbacks.
- The technology and frameworks are constantly changing. This means, that after a few years, the community may move towards a newer, better maintained and fresher system. This leaves the older ecosystem to very slowly fade away. This also indicates that there is a lot of market fragmentation. A lot of frameworks have designed the same tools for themselves.
- The quality of most packages in the JavaScript/Node ecosystem is low, though there are really good ones!
- JavaScript lacks types, which does make the code more brittle as it grows. This is why TypeScript was developed by Microsoft.
-
The main interpreter implementation is improving performance, safety and adding newer features. However, PHP does show its age, see
$for variable indentifiers. Most new projects do not use it, though it has some very well-known and powerful frameworks. There are also tools such as PHPStan that serve as code analysers and help keep the quality of the code high. ↩ -
Just like with Common Lisp, Ada seems an odd choice. However, its extreme focus on quality, maintainability and readability do check the most important properties in a robust system. Therefore, it is added to the list for completeness. ↩
-
The addition of Common Lisp, from now on CL, may seem like a strange and out of touch addition, as it is a language that basically no body uses in large complex systems. However, since this project requires the interoperation of so many tools and data systems, CL does provide a large advantage as it can be used as a meta-programming language for all. This is, in the end, the biggest strength of CL. ↩
-
Single Board Computers. ↩
-
The license of ArangoDB was changed in early 2024 and it is no longer open source. ↩ ↩2
-
3 year period. Acceptable. ↩
-
Docker is not recommended. ↩
-
Manual build is based on Bazel, a Java based build system. It also requires a C++ compiler. ↩
-
The license was changed from MPL v2 to BSL mid-late 2023… ↩
-
MongoDB “drop-in” replacement . ↩
-
MongoDB “drop-in” replacement . ↩
-
It is a multithreaded fork of Redis. ↩
-
Timescale extension. For fully libre implementation, compile with
-DAPACHE_ONLY=ON. It has some features behind their own non-libre license, which is a problem. They also deprecated Promscale, a storage and OpenTelemetry compatible DB. Furthermore, their DB Tookit is not libre. ↩ -
With the pgvector extension. ↩
-
See the PostgreSQL build for Supabase. ↩
-
Timescale extension. For fully libre implementation, compile with
-DAPACHE_ONLY=ON. It has some features behind their own non-libre license, which is a problem. They also deprecated Promscale, a storage and OpenTelemetry compatible DB. Furthermore, their DB Tookit is not libre. ↩ -
Single Sign On ↩
-
Multi Factor Authentication ↩
-
Official support is only for Linux, Windows, Android and Macs. Community support also runs it on *BSD systems. ↩
-
The Modelica license is an open license that does not allow the selling of the licensed product by itself. It can only be sold when packaged with a value added asset. ↩
-
OpenRadioss is not fully open. It has a couple of visualization and processing tools that are closed. ↩
-
This is not entirely true. Other systems can be used. However, LaTeX is the most common one and it generally creates the most consisten output. ↩